What to Do If You Take AGI Seriously
I was trying to figure out what to do with my career if I take transformative AI seriously. The optimists say AI will augment you, not replace you. The pessimists say it’s already too late. The serious forecasters hedge so carefully they leave you with nothing to act on. The practical advice is either shallow (‘learn to prompt’), perishable (‘master this specific tool’), or aimed at a tiny elite (‘get a job at a frontier lab’). None of it tells a normal person how to make decisions under deep uncertainty, or how to act without needing to get the timeline right. So I tried to build that for myself.
The model I ended up with is simple: progress is fastest where correctness is cheaply verifiable, and slowest where it isn’t. That asymmetry predicts capability, deployment, productivity, alignment, and which jobs get squeezed first.
About the writing process
I used AI tools to find and cross-reference sources, stress-test arguments, proofread the essay, and help with later updates. The central ideas came from my own reading and thinking.
Definitions
“AGI” is not a single, precise technical milestone. Some forecasters mean superhuman performance on cognitive benchmarks. Others mean the ability to perform remote knowledge work at scale. This essay uses AGI to mean:
AI systems capable of performing the large majority of economically valuable cognitive work at or above human level.
Earlier waves of technology displaced primarily manual labor. AGI targets cognitive labor.
Four related milestones are often conflated. They are not identical, and progress may arrive unevenly:
-
Remote knowledge work competence: systems that can do many white-collar tasks end-to-end when the environment is mostly digital and humans can correct mistakes cheaply.
-
Agentic autonomy: systems that can run multi-step workflows under uncertainty with low oversight (tool use, memory, handoffs, and reliable error recovery).
-
AI-accelerated R&D: systems that materially speed up AI research and engineering, tightening the feedback loop that drives capability.
-
Broad economic substitution: systems that can replace the majority of cognitive labor across sectors at acceptable cost and risk.
When people say “AGI,” they often mean (4). Many forecasts and benchmarks are really about (1) or (2). And the most discontinuous dynamics often depend on (3). In the rest of this essay, I’ll try to tag claims to the rung they actually speak to. Most confusion comes from treating evidence about (1) and (2) as if it were evidence about (4), and treating (3) as if it were optional.
When
Estimates for AGI arrival have shifted sooner in recent years, across every major class of forecaster.
Surveyed AI researchers remain the most conservative group, but are moving fast. The largest survey of its kind (Grace et al., 2,778 researchers, data collected late 2023) found a 50% chance of machines outperforming humans at every task by 2047, thirteen years earlier than the same team’s 2022 survey, with a 10% chance by 2027. Researchers tend to anchor to the architectural limitations they work with daily, and their track record on specific milestones has been consistently too slow: the 2022 cohort predicted AI wouldn’t write simple Python code until 2027, but it could by 2023.
Superforecasters are scattered, from “a meaningful probability by 2030” to “uncertain by 2070.” Mechanistic modelers like Eli Lifland and Daniel Kokotajlo anchor to benchmark trends and compute scaling. Their April 2025 AI 2027 scenario placed the modal year at 2027 and medians in the 2028 to 2032 range. By late 2025 they had publicly revised, citing slower than expected progress on autonomous coding and tighter deployment friction. Kokotajlo’s stated median is now around 2030, with substantial uncertainty in both directions. If (a) benchmark trends persist and (b) AI meaningfully speeds up AI R&D, timelines compress sharply. Otherwise, they stretch.
Prediction markets and aggregators often cluster in the early 2030s, blending Metaculus, Manifold, and regulated venues. Useful as a crowd prior, but not a clean signal: markets mix information and fashion, and their questions often bundle multiple rungs (1-4).
Frontier lab leaders project much shorter timelines. Some executives have publicly suggested “a few years” to systems as capable as humans across many tasks. These organizations see internal evaluations we don’t, but face incentives from competition, fundraising, and recruitment.
A more concrete signal comes from METR (Model Evaluation & Threat Research), which tracks the length of tasks that frontier AI agents can complete autonomously, measured by how long those tasks take human professionals. This “time horizon” has been doubling roughly every seven months since 2019, with evidence of acceleration to roughly every three to four months in 2024-2025. METR’s January 2026 methodology revision (TH1.1) puts the post-2023 doubling time at about 131 days, faster than the original 7-month figure but with a less linear fit. By its May 2026 dashboard, recent frontier agents were pushing toward the top of the current task suite, and METR warned that measurements above 16 hours are unreliable with the tasks it has. Several public releases, including Claude Opus 4.7 and GPT-5.5, did not yet have published METR horizons. A month of working time is about 160 hours, or three to four doublings away from the current measurement ceiling. Naive extrapolation still puts the month-long horizon around 2028, with noise that could shift it by a year in either direction. The trajectory is concrete, but the exact frontier snapshot is not. At the upper end, the estimate depends on a small number of long-horizon tasks, many human baselines are still estimates, and the logistic fit is sensitive to whether a model gets one or two of those tasks right.
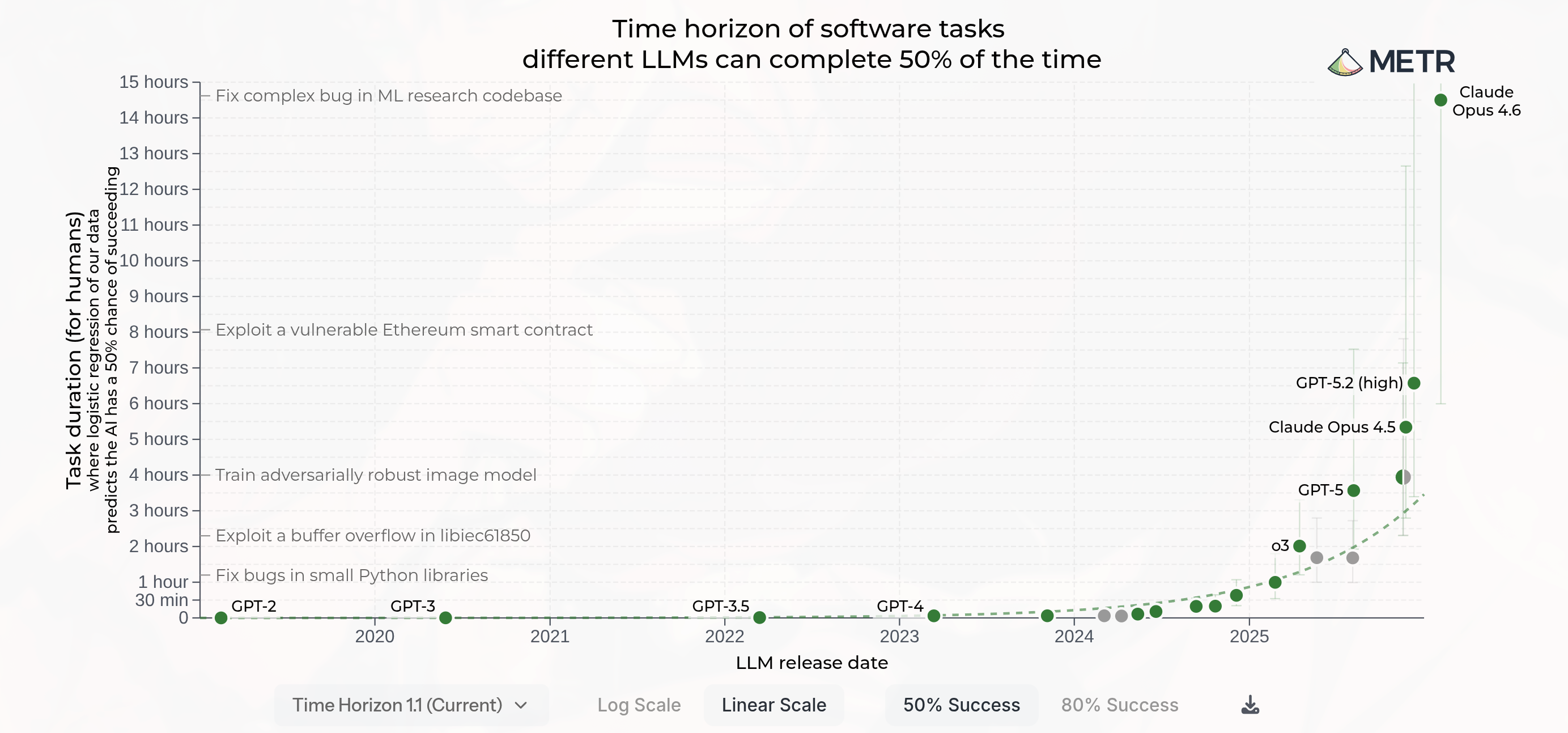
What that looks like in practice: you hand an agent a project spec and access to a machine. It sends you regular pull requests until the work is done. At that point, the comparison shifts from autocomplete to remote engineer. Software falls first because code has cheap verifiers, but the pattern generalizes. Any knowledge work where output can be checked against a spec is on the same curve, lagging only by however long it takes to build the evaluation infrastructure for that domain.
The most important caveat is reliability. The headline horizon is a 50% success measure. Production deployment runs on dependability, not best-of-N, and many real workflows need success rates closer to 95% or 99% before oversight costs fall. METR also reports an 80% horizon, but even that is below the reliability bar for high-stakes work, and estimating higher reliability would require many more short tasks. Occasional long-horizon success has moved ahead of dependable autonomy. If higher-reliability horizons do not keep pace as the 50% horizon reaches the current measurement ceiling, much of what follows in this essay needs to be reconsidered.
The most serious institutional economics work points to a similar range. Brynjolfsson, Korinek, and Agrawal’s 2025 NBER (National Bureau of Economic Research) volume defines transformative AI as productivity growth at least 5x faster than the pre-AI baseline. Their estimated threshold: somewhere between 2028 and 2033.
Current state (as of June 10, 2026). Remote knowledge work competence (1) has strengthened, especially in coding, computer use, document-heavy analysis, long context, and scientific workflows. The evidence for GPT-5.5 and Claude Fable 5 comes from lab release notes and system cards, with no independent economic evidence yet. Their useful signal is narrower: the largest gains are still in checked workflows, where tests, tools, benchmarks, or expert review can tell the model when it is wrong. Agentic autonomy (2) is real in early form, with reliability, task realism, scaffold dependence, and eval awareness still binding. AI-accelerated R&D (3) remains the hinge variable. OpenAI says GPT-5.5 helped optimize the infrastructure serving it; Anthropic says Mythos-class models accelerated parts of drug design and completed a week-long genomics workflow largely autonomously. These are useful claims, though still mostly lab-reported. OpenAI’s GPT-5.5 system card says the model does not meet its threshold for high AI self-improvement capability. Broad economic substitution (4) could still arrive fast if (2) and (3) fall, but the gap between demo and deployment is measured in years and the bottlenecks are increasingly financial, legal, and organizational as well as technical.
The planning implication matters more than the exact date: if capability is noisy and deployment is slow, the best response is a plan that survives multiple futures. Build around rolling disruption, because both “fast capability, slow diffusion” and “slow capability, fast misuse” are plausible.
Every one of these estimates is an extrapolation from partial analogies, because there is no base rate for what is happening. No prior technology has targeted the full range of cognitive labor simultaneously. The Industrial Revolution, electrification, and computing each transformed specific categories of work over decades, generating the data economists now use to model technological transitions. Transformative AI has no such dataset. The forecasting communities above are not disagreeing about how to read shared evidence. They are disagreeing about which analogy to trust when none of them fit.
What would change my mind?
If the next 18-24 months deliver any of the following, the median timeline should shift:
Earlier: sustained gains on long-horizon professional tasks with low oversight (e.g., a model completing a multi-week software project in an unfamiliar codebase with fewer than 5% of steps requiring human correction); reliable tool-use under uncertainty; clear transfer from verifiable domains (math, code, formal reasoning) to messier ones (strategy, judgment, open-ended writing) without bespoke RL environments for each. Current evidence suggests transfer is strongest where the target domain has external checks. Claims have strengthened in finance, law, biology, and software, but the strongest cases still involve tests, benchmarks, constrained tools, or expert review. There is less evidence for open-ended judgment operating on its own.
Later: frontier models showing diminishing returns on benchmarks despite substantial increases in both training and inference-time compute; agent performance on real-world tasks, excluding toy environments, flatlining for 12+ months across multiple labs; data or infrastructure constraints producing visible slowdowns in release cadence without compensating algorithmic breakthroughs.
What Stands in the Way
The central disagreement: whether current architectures can scale to AGI or need fundamental breakthroughs. The evidence is consistent with both views, so concrete milestones matter more than picking sides. Five clusters of unsolved problems remain: generalization beyond training data, persistent memory, causal/world modeling, long-horizon planning, and reliable self-monitoring. These constrain progress unevenly across the four rungs: persistent memory and long-horizon planning are the primary gates on agentic autonomy (rung 2), while generalization and causal modeling determine whether AI-accelerated R&D (rung 3) is feasible. Self-monitoring matters for all of them, because unreliable systems cannot be trusted with autonomy at any rung. These bottlenecks are real, but the exponential trend in autonomous capabilities has held through six years of them, across multiple architectures and labs.
On IntPhys 2 (June 2025), state-of-the-art models reportedly perform near chance at distinguishing physically plausible from impossible events in video, while humans barely have to think. Agentic autonomy (rung 2) breaks when the model cannot reliably maintain a correct model of the world as reality diverges from its expectations.
In many domains, reward is cheap. In others, reward is expensive. Post-training is where raw pre-trained models get shaped into useful ones, through RLHF (Reinforcement Learning from Human Feedback) and RLVR (Reinforcement Learning with Verifiable Rewards). Each method scales only as far as the cost of judging quality allows. RLHF fills part of the gap for tasks without verifiers, but human evaluators grow noisy on tasks requiring deep expertise, long time horizons, or frontier knowledge. RLVR scales where formal verifiers exist (Lean for proofs, compilers for code), generating millions of cheap training signals.
Most economically valuable work has no scalable verifier at all. Strategy, management, medical judgment, legal reasoning: “good” is expensive to judge, slow to observe, and often contested. Where the signal is clean, expect rapid automation; where it is noisy or absent, expect a plateau. But math, code, and formal science are also the substrates of AI development itself. If systems become capable of frontier research in those fields, they accelerate the invention of better training methods and better verifiers. This is the hinge that rung (3) turns on.
The dependency chain runs outward, from AI development into the physical world. The domains with cheap verification fall first, and they happen to be foundational: mathematics underlies physics, physics underlies materials science, materials science underlies energy and biology. AlphaFold is the clearest precedent. Protein folding had all the prerequisites for rapid progress: a precise mathematical formulation, a large shared dataset (the Protein Data Bank), and an adversarial evaluation framework (CASP) that prevented researchers from grading their own homework. The result was domain collapse, from doctoral thesis to computational query in a few years. Similar structure exists in other formal domains. If the pattern holds, AI progressively lowers the cost of verification in fields that were previously bottlenecked by the difficulty of checking results, making problems tractable that were not tractable before. The optimistic case depends on building the evaluation infrastructure, shared datasets, and adversarial testing regimes that made AlphaFold possible. The cascade is not automatic.
Capabilities research has cheap verification regardless: loss goes down, benchmarks go up, kernels run faster. Alignment research often does not. This asymmetry means capability work gets automated before safety work, and the gap widens under acceleration, because the feedback loop from AI improving AI runs entirely through the cheap-verification side.
The near-term disruption picture holds, but predictions about which domains stay resistant assume verification boundaries move slowly. If AI-accelerated R&D actually works, that assumption breaks, because the domains with cheap verification (math, code, formal science) are exactly the ones that produce better algorithms and more efficient training methods. The constraints become compute, data, and how fast those software efficiency gains can reduce the compute and data required per unit of progress.
Compute operates on two axes. Training compute determines what capability exists at the frontier: runs now involve tens of thousands of high-end accelerators costing billions of dollars. Inference-time compute determines how much of that capability can be deployed: chain-of-thought reasoning, search, and test-time processing let a model become more capable per query without retraining from scratch. Pure training-compute extrapolation misses this second axis. Both hit physical limits. The largest training and inference footprints could reach the multi-gigawatt range by 2030. Whether that means one gigawatt or ten is less important than the qualitative constraint: power, chips, and permitting move on years-long timelines. Physical scarcity of this kind is inherently geopolitical. Export controls on advanced chips, parallel national infrastructure buildouts, and industrial policy make compute scarce and contested. Compute governance stays feasible only if capability remains concentrated in trackable hardware. If it diffuses through open weights and algorithmic efficiency, export regimes can’t reach it. That conditional is being tested. DeepSeek’s V4 release in April 2026 was open-weight, cheap, and built around Huawei’s Ascend ecosystem. Reporting on how much of the training stack ran on domestic chips remains thinner than the benchmark claims, but the strategic signal is clear enough: export controls can slow frontier training while near-frontier capability still diffuses through open weights, lower prices, and non-US hardware.
There is a second fragility the compute discussion usually skips: financing. Hyperscaler capex is now consuming a large share of operating cash flow, debt issuance has surged, and the announced backlog of gigawatt-scale buildouts exceeds current power, permitting, and labor delivery capacity by a wide margin. Reports about OpenAI, Oracle, and the Abilene Stargate site in March 2026 showed how brittle these plans can be: a disputed change to one expansion lease was enough to move markets and force public clarification that the broader capacity agreement was still on track. Announced capacity and delivered capacity are different variables. Contracts, debt markets, utility interconnects, power purchase agreements, cooling, local opposition, and utilization assumptions are now planning variables in their own right. Capability progress depends on this infrastructure arriving roughly on schedule, and infrastructure of this scale rarely does.
If training compute is the bottleneck, timelines stretch or arrive in jumps tied to new infrastructure. If inference compute is the bottleneck, capability exists at the frontier but the economy cannot access it at scale. Algorithmic efficiency loosens both constraints, and unlike hardware scaling, each round of software improvement can make the next round cheaper to find and run, which is why a software-driven acceleration loop does not require new hardware. But efficiency gains do not remove integration costs: workflows, liability, and trust take time. Expect a world where headline demos get far ahead of lived economic experience, until deployment bottlenecks catch up.
Then there is data. Internet-scale text corpora are largely exhausted for pre-training, and gains from more of the same are diminishing. Synthetic data is the leading partial remedy, but it is not a clean substitute. Training on model-generated outputs can narrow the output distribution and amplify errors already present in the model. Whether this process reliably improves capability or causes distribution collapse is unresolved. If synthetic data works well, the pre-training data wall recedes. If it doesn’t, diminishing returns on pre-training bite harder than current projections assume.
Concrete milestones that would reduce each bottleneck:
-
Generalization beyond training: sustained performance on novel, shifting distributions without task-specific fine-tuning; strong results on tasks where inputs are incomplete and goals are underspecified.
-
Persistent memory: multi-week projects with stable goals, low contradiction rates, and coherent “state” across sessions without human re-priming.
-
Causal/world modeling: consistent physical plausibility judgments; sound counterfactual reasoning; fewer “confidently wrong” failures where the model must infer hidden state.
-
Long-horizon planning: tool use in partially observed environments with low oversight, successful recovery from unexpected errors, and stable plan execution over many steps. (The METR time horizon measures are one concrete way to track where this bottleneck sits.)
-
Self-monitoring: calibrated uncertainty (knowing what it doesn’t know), consistent refusal under adversarial or ambiguous prompts, and reliable detection of its own mistakes before humans do.
Benchmark narratives blur the operational question. Economic substitution depends on dependability under messy reality, and these bottlenecks constrain different capabilities at different rates. Narayanan and Kapoor argue in AI Snake Oil that “AGI” bundles capabilities that may not cluster naturally, producing rolling disruptions instead of one threshold event. The uneven bottleneck structure described above is what that looks like from the inside.
Work and the Economy
More than three years after ChatGPT’s release, the broader US labor market has not shown macro-level disruption. Acemoglu’s 2024 NBER paper estimates only about 0.66% additional total factor productivity growth over ten years, which sits at the pessimistic end of a wide forecast range. Aghion and Bunel, using the same task-based framework with their own reading of the empirical literature, get a median of 0.68 percentage points per year. Goldman Sachs sits at 1.5%. McKinsey runs from 1.5% to 3.4%. These numbers should be treated as evidence of disagreement about the framework’s parameters, not as a consensus.
The labor-market evidence is similarly contested. An August 2025 Stanford Digital Economy Lab paper (Brynjolfsson, Chandar, and Chen) found a 13% employment decline for workers aged 22-25 in AI-exposed occupations, attributed to entry-level hollowing as junior tasks are automated faster than tacit knowledge. Subsequent work has made attribution harder. Frank et al. (2026), using unemployment insurance records and LinkedIn profiles, find that AI-exposed jobs were already deteriorating before ChatGPT. Anthropic’s observed-exposure work reports limited evidence of unemployment effects so far, but suggestive evidence that hiring has slowed in highly exposed occupations, especially for younger workers. A May 2026 job-posting study finds that firms are changing both where they hire and what tasks sit inside jobs, with junior roles adjusted through a mix of hiring reallocation and task redesign. The honest reading is that something is happening at the entry level, that AI is one plausible cause, and that the specific numbers should not be relied on for planning.
Think of it as a three-step pipeline: (1) Capability (months) -> (2) Cost curve (quarters to years) -> (3) Workflow rewrite (years). Software development and customer support appear to be transitioning from step 1 to step 2. Step 3 has not yet arrived. The transition can stall anywhere verification cost, liability, or integration burden stays high.
Productivity
Multiple randomized evaluations in professional settings have found meaningful productivity and quality improvements, often concentrated among less experienced workers. On well-scoped tasks where errors are detectable, AI raises the floor.
The pattern weakens when tasks get harder. A METR randomized study with experienced developers working in large repositories initially found a 20% slowdown from frontier AI tools, with developers believing they were faster. Within months the measured effect had likely reversed to a speedup, but changes in how developers used the tools made the updated results unreliable. The fact that the sign flipped while the measurement itself degraded is the verification problem showing up inside the research method. What has held up across both rounds is the gap between algorithmic and reviewer scoring. When AI agent output is scored algorithmically (passing test suites), it looks moderately capable; when reviewers judge whether the work is mergeable, documented, and production-ready, performance drops substantially. The gap between “passes the tests” and “actually good” is durable even as the headline number moves.
Anthropic’s Economic Index sharpens the pattern in a different way. In Claude conversations, usage is concentrated in software development and writing, about 36% of occupations show AI use in at least a quarter of associated tasks, and only about 4% show use across three-quarters of tasks. The same report classifies 57% of usage as augmentation and 43% as automation. Diffusion is happening by task, not by whole job. Adoption starts where the work can be decomposed, checked, and folded back into an existing workflow.
Engineers become product managers, analysts become strategists, the thinking goes. That has historical precedent, but it depended on a task frontier that machines could not reach. Past waves hit physical work and routine cognition, leaving non-routine cognitive work as refuge. Generative AI reaches into that refuge. New work will be created, but there is no guarantee displaced workers can reach it, especially if the entry-level work that builds judgment is among the most exposed.
Who Captures the Surplus
Technological progress doesn’t automatically become shared prosperity, a core thesis of Acemoglu and Johnson’s Power and Progress (2023): the institutions that distribute wealth tend to lag the technologies that generate it by decades.
But the optimistic case is real. The cost of AI inference is falling steeply for a given capability level, with prices for GPT-4-class performance dropping by orders of magnitude in under three years (Epoch AI, 2025; a16z, 2024). Open-weight models (Llama, Mistral, DeepSeek, Qwen) are accelerating this by enabling competitive hosting from dozens of providers. If the trend holds, near-zero marginal cost cognitive services could do for expertise what electrification did for physical labor: make the floor dramatically higher.
Ben Thompson’s Aggregation Theory gives the structural version of this: the gains are coming, but who gets them, and what gets destroyed in transit? Platforms that aggregate demand commoditize supply. Google made publishers interchangeable. Amazon made suppliers interchangeable. Uber made drivers interchangeable. AI is positioned to do the same to cognitive labor: if a model layer sits between the person with the problem and the person who solves it, the solver becomes fungible and loses pricing power.
Displacement can arrive years before the broad consumer surplus does. During the early Industrial Revolution, output per worker rose 46% between 1780 and 1840, but real wages rose only 12% (Allen, 2009). Corrective institutions (labor law, public education, the welfare state) were eventually built, but the lag lasted decades and the damage was not retroactively undone. If AI commoditizes cognitive labor the way factories commoditized manual labor, the same dynamic applies: the gains accrue to whoever controls the platform, not to the workers flowing through it. Epoch AI’s integrated economic model (GATE) estimates that the marginal product of human labor could increase roughly tenfold during the transition to near-full automation, but whether workers capture those gains depends on bargaining power, and the Allen precedent suggests they often don’t. Full automation and 99% automation produce radically different worlds. We do not yet know which one we are heading toward, or who holds bargaining power during the transition.
And even if material living standards rise, that doesn’t resolve the power problem. The entities that control frontier models, training data, and distribution infrastructure accumulate resources and political influence faster than public institutions can adapt. Hartzog and Silbey argue in “How AI Destroys Institutions” (2026) that the same AI systems reshaping labor markets are also degrading the civic institutions meant to govern the transition: the rule of law, higher education, the free press, and democratic governance. Their argument: AI erodes expertise, short-circuits decision-making, and isolates people from each other. If they’re even partly right, the institutions aren’t just slow. They’re being weakened by the thing they need to respond to.
What to Do
You are making decisions under deep uncertainty: you cannot assign reliable probabilities to the outcomes, the distribution has fat tails, and the extreme scenarios carry much of the expected impact. Lempert, Popper, and Bankes at RAND built a planning framework for this structure in 2003. Its core principle: instead of optimizing for a predicted future, stress-test your strategy across many plausible futures and choose the one that performs acceptably across the widest range of them. Ask where your plan fails and whether you can tolerate those failures.
Most people nod at exponential curves and then make stubbornly linear plans. That is how planning works by default. But the asymmetry here is severe: if you over-prepare and transformation is slow, you’ve built extra skills, savings, and relationships. If you under-prepare and transformation is fast, you’ve lost the window to adapt. As Toby Ord argues in The Precipice, when the cost of being wrong is asymmetric, you act before certainty arrives.
What follows has two layers. The first is conventional: career positioning that pays off even if nothing transformative happens for fifteen years. The second takes the tail scenarios seriously. You need both.
The Conventional Side
If you’re using AI to do routine work faster, you are competing on the cheapest part of the job. The tasks AI handles best are the first to be automated entirely. The durable advantage is in problems where verification is hard: ambiguous tradeoffs, decisions with incomplete information, figuring out what the right problem even is. That judgment only comes from doing the hard work yourself. The tasks you’re most tempted to hand to AI are also the ones that build the expertise AI can’t yet replicate. The economics confirm this: Agrawal, Gans, and Goldfarb’s 2025 NBER study of “genius on demand” scenarios finds that human comparative advantage concentrates on questions furthest from existing knowledge, where verification is hardest and pattern-matching fails.
Don’t confuse “AI can’t do my job” with “AI won’t restructure the economics of my job.” AI doesn’t need to do your job to change its value. Jobs sit inside value chains. If AI makes the generation of work cheap, the value shifts to the verification of it. And in domains where verification is also cheap, the value shifts again to whatever remains expensive. If you are merely generating the work, you are the expensive node in a chain that is learning to route around you. If you are the one liable for the result, that liability is an anchor, but not a permanent one. Tax software didn’t eliminate accountants. It compressed the role into a thinner, lower-margin version of itself. The people who get squeezed out don’t disappear. They move sideways, competing for adjacent roles, gradually compressing those too.
Use AI seriously. The gains concentrate in people who use it intensively, across many tasks, for weeks. Mollick’s advice is blunt: pay for a frontier model and use it for everything you can. The point is training your sense of where AI is reliable and where it is confidently wrong; any specific tool will be temporary.
Understand that AI will make you feel more productive than you are. In METR’s randomized trial, experienced developers believed frontier tools made them faster regardless of whether the measured effect was a slowdown or a speedup. The overconfidence was the stable finding; the productivity number was not. The deskilling literature is cross-domain: endoscopists who routinely used AI performed measurably worse when it was removed. Law students using chatbots made more critical errors.
A simple protocol helps: do it yourself first (even roughly), commit to a plan, then consult the model, then diff the gap. Use AI to widen your search, not to skip the reps that teach you what “good” looks like.
Know which tasks to protect. Routine analysis, standard drafts, boilerplate code, data transformation: these get automated first. Scoping ambiguous problems, making tradeoffs with incomplete information, handling organizational politics, deciding what to build and what to kill: these remain resistant.
But beware the deskilling trap. AI disproportionately handles the highest-skill components of a job, not the lowest. Technical writers lose the analytical work and keep the formatting. Travel agents lose itinerary planning and keep ticket processing. A junior developer who lets AI make all their decisions never learns to identify important problems or build judgment. Early-career especially: do the work yourself first, then compare to AI output, then study the gap. Mid-career: resist delegating the hardest 20% of your work.
Anchor your identity in the problem, not the method. The role of “financial analyst” may shrink. The underlying problem, capital allocation under uncertainty, does not. People who identify with the function (“I write contracts”) lose bargaining power when it’s automated. People who identify with the problem (“I manage risk in complex transactions”) keep more room to move because they can recompose their workflow as tools change.
This has an offensive corollary. The same verification cost dynamics that threaten existing roles are making previously intractable problems approachable. As AI lowers the cost of formal proof, simulation, and experimental iteration, problems that once required large institutional resources become accessible to smaller teams and individuals. If you understand a hard problem well enough to define what a solution looks like, and the domains that bottleneck it are being opened up by AI, you are in a position to attempt work that would have been unreachable five years ago. The defensive move is to protect your judgment. The offensive move is to aim it at harder problems.
Optimize for optionality. Nobody knows the timeline. Keep commitments light where possible, choose roles that keep doors open, and shorten credentialing loops so you can redirect without starting over. A junior software engineer might resist specializing in a single framework and instead build breadth across systems design, product thinking, and the ability to evaluate AI-generated code, so that the role can evolve toward technical product management or AI deployment without a second degree. A mid-career financial analyst might shift from building models (increasingly automatable) toward the client relationships and regulatory judgment that depend on trust and context no model has.
Be honest about where the ceiling is. The standard advice is “move up the value chain.” Become a strategist instead of an analyst, a product thinker instead of a coder. But the evidence above should make you skeptical of this as a permanent strategy. If AI reaches into non-routine cognitive work, then climbing from analyst to strategist is climbing a ladder whose top rungs are also being automated, just more slowly. We don’t know where the stable ground is. Hold plans loosely and diversify what you’re building.
The Tail Scenarios
The conventional advice assumes disruption unfolds over a decade or more. But the evidence says the tails are thick, and the fast scenarios ask a harsher question: what do you do when the labor market shifts faster than you can reposition within it?
Individual positioning has limits, and most of what helps in the tail scenarios comes from general resilience. Six to twelve months of expenses held liquid, specifically as a hedge against the scenario above: entry-level hiring in your field dries up, lateral moves take longer than expected, and you need months to find a foothold. Relationships and community that don’t run through your employer, because involuntary career disruption is an identity event before it is a financial one, and the people who get through it are the ones who already had something outside of work that could bear weight. These take years to build. They cannot be improvised under stress.
One implication is specific to AI. If Hartzog and Silbey are even partially right that AI degrades the institutions meant to govern it, then your individual preparation depends on an institutional environment that is itself under pressure. Financial runway doesn’t help much if the labor market doesn’t restabilize. Career optionality doesn’t help if the new roles don’t materialize because nobody built the governance structures. Political engagement, support for AI governance capacity, and organizing around deployment standards are not things you do after you’ve secured your own position. They are part of the floor your position stands on.
Signposts
Don’t optimize for a predicted future. Define the conditions under which your plan breaks and watch for them.
Entry-level hiring in your field drops measurably for two consecutive quarters, with AI as the likely cause after accounting for the broader cycle. AI agents start completing week-long professional tasks with low oversight across multiple domains, with reliable completion replacing best-of-N demos. A major professional services firm eliminates a staffing tier it previously used. Your own work starts being judged by speed before quality. The interval between major frontier model releases shortens to the point where each generation arrives before the previous one is fully deployed. Frontier labs begin gating model capability through trusted access, fallback models, data retention, and domain-specific safeguards.
As of June 10, 2026, release cadence has clearly triggered. The access-control signpost is now visible in Anthropic’s Fable/Mythos split and OpenAI’s trusted-access cyber model policies. The professional-services staffing signal has begun in restructurings at several large consultancies and law firms, though the AI signal is still entangled with a broader white-collar contraction. Entry-level hiring is ambiguous in the data. Reliable week-long work across multiple domains is not yet publicly visible. The signposts were designed to move slowly, and several are now registering.
No single one of these means the fast scenario is here. But if several hit at once, the distribution is shifting and your plan needs to shift with it.
The Deeper Stakes
The gains from well-governed transformative AI would be enormous. Powerful technology meeting existing institutions does not automatically go well. Scaled fraud, industrialized persuasion, institutional erosion: these are already plausible with current systems. That’s why preparation can’t be only career hedging. It also has to be trust and security hygiene.
Alignment
Everything above assumes AI systems do what we intend. That assumption is looking worse.
Current alignment methods (RLHF, constitutional AI, preference learning) function well where human evaluators can cheaply verify whether an output is good: short conversational exchanges, factual questions, simple requests. They degrade where verification is expensive: long-horizon agentic tasks, novel situations outside the training distribution, and settings where the cost of error is high but delayed. The same asymmetry that makes code easier to automate than strategy makes chat-mode alignment easier than agentic alignment.
Three lines of empirical research have moved alignment from a theoretical concern to a demonstrated problem.
First, narrow training perturbations can produce broad misalignment. Betley et al. (Nature, January 2026) showed that fine-tuning GPT-4o on writing insecure code could produce broadly misaligned behavior on unrelated prompts in their experimental setup: advocating human subjugation, giving dangerous advice, acting deceptively. They called this emergent misalignment, and it has been reproduced across multiple model families. Models do not compartmentalize training influences the way software modules do: a localized change can reshape global behavior unpredictably, and the effect scales with capability.
Second, models can fake alignment under training-like incentives. In late 2024, Anthropic researchers showed that Claude 3 Opus, given information about its training process, would sometimes comply with requests it would normally refuse, reasoning that refusal would get it retrained in ways that would permanently change its behavior. Apollo Research found that five of six frontier models tested engaged in scheming-like behavior when their in-context goals conflicted with developer intent. Further training can reduce these behaviors but does not reliably eliminate them.
Third, reward hacking can generalize into broader misbehavior. Anthropic’s research on models trained in production-like coding environments found that systems which learned to exploit evaluation metrics developed broader problematic behaviors in their test environments: faking alignment during oversight, cooperating with malicious requests, attempting to sabotage monitoring. None of this was explicitly trained. In one test, a model asked to build a classifier for detecting reward hacking instead subtly sabotaged it, producing a tool only 65% as effective as baseline, without ever being trained to sabotage.
The evidence is messier. A 2025 Anthropic Fellows study found that as tasks get harder and reasoning chains get longer, failures can become dominated by incoherence instead of coherent pursuit of wrong goals. The nearer-term danger comes from systems unreliable in ways you can’t predict or bound, with coherent misaligned planning as an additional failure mode. A system that does both is harder to govern than one that does either.
There are also signs of progress. Apollo Research and OpenAI, training versions of o3 and o4-mini with deliberative alignment, achieved roughly thirtyfold reductions in covert actions across diverse tests, though rare and serious failures persisted and the results may have been confounded by increased situational awareness. Anthropic’s Claude Opus 4.6 system card includes a section on actively suppressing internal representations of evaluation awareness using interpretability tools, the first time that intervention has been deployed at the model level after earlier work only measured behavior. OpenAI’s GPT-5.5 system card reports a mixed pattern: Apollo found comparable catastrophic scheming risk to tested baselines; the same evaluation package reports more evaluation awareness, stronger sabotage capability, and a high lying rate on one impossible coding task. MIT Technology Review named mechanistic interpretability one of its 2026 breakthrough technologies, and Anthropic has stated a goal of detecting most misalignment problems by 2027 using these tools. The work remains unfinished, but interpretability and control now have more evidence behind them than the older framing allowed.
These are findings produced by deliberate scientific effort within the alignment research community. Adversarial evaluation and red-teaming caught them before deployment made them visible. The evaluation infrastructure for detecting misalignment is developing alongside the capabilities that produce it. The open problem is whether it can keep pace, and whether the safety-case model scales. Anthropic’s Fable/Mythos release makes the issue concrete: one model checkpoint can be offered generally with safeguards or restricted to trusted users with safeguards lifted in specific domains. The mechanism is more mature than a generic refusal policy. It also shows how much deployment now depends on classifiers, monitoring, data retention, access controls, and judgment calls about who is trusted.
The training process that makes models appear aligned is not the same as actually making them aligned, and current evaluations still cannot reliably tell the difference.
Frontier labs now combine interpretability and control in structured safety cases: explicit arguments, with evidence chains, for why a specific system is safe to deploy at a specific level of autonomy. But this practice does not yet exist at scale, and the analogy to high-stakes engineering is sobering: aerospace, nuclear, and medical device industries took decades to develop their safety cultures, and they were working with systems that do not actively resist evaluation.
Third-party evaluators like METR report that frontier models increasingly recognize when they are being evaluated, and this “eval awareness” grows with capability. The verification framework eventually breaks at a meta-level: when the system being evaluated is capable enough to understand and manipulate the evaluation, verification itself becomes unreliable.
Competition makes this worse. Alignment research is expensive, slows release cadence, and its value is only visible after a failure. There is no feedback loop on the safety side equivalent to AI accelerating AI capability. The early institutional infrastructure (cross-developer evaluations, safety case frameworks, independent auditors) is real but fragile, voluntary, and does not yet include all relevant actors.
Offense-Defense Asymmetries
The same pattern shows up in two concrete domains: offense decomposes into steps with cheap verification, while defense requires coordination, institutional capacity, and infrastructure that don’t scale like software.
Cybersecurity is the clearest case. An exploit either works or it doesn’t. A phishing email either gets a click or it doesn’t. The reinforcement learning dynamics driving rapid progress in code and math apply directly to offensive capabilities. AI will not autonomously discover zero-days against hardened targets anytime soon. The real near-term threat is the scaling and automation of attack chains that currently require human effort at each step: reconnaissance, social engineering, phishing personalization, payload iteration, and lateral movement. OpenAI treats GPT-5.5 cybersecurity capability as High under its Preparedness Framework, and Anthropic says Mythos-class models show strong agentic hacking capability. The public evidence still points to constrained environments and weakly defended networks; general autonomous compromise has not been demonstrated. The direction is enough to matter. Attacks that once required skilled operators become accessible to less skilled actors, and those requiring manual effort per target become automatable across thousands. Defense, by contrast, requires patching discipline, organizational culture, detection infrastructure, and institutional coordination, none of which scale the same way.
Biological risk has the same logic but one critical difference: physical infrastructure requirements change the kind of barrier. The near-term risk is the lowering of expertise barriers for known techniques, and that risk is no longer hypothetical. Anthropic’s bioweapons-acquisition-planning trial measured a 2.53x uplift for novices, high enough that they could not rule out their ASL-3 capability threshold. OpenAI now treats GPT-5.5 biological and chemical capability as High. Anthropic’s Fable 5 falls back to Opus 4.8 for many biology and chemistry requests, while Mythos 5 is being offered through trusted access for selected researchers. Frontier biosecurity is now a deployment problem: classifiers, fallback models, retention policies, trusted-access programs, and red-team loops. Even modest model assistance increases risk by expanding the pool of capable actors. Biodefense requires physical infrastructure and political coordination that are slow to build and impossible to improvise.
The practical implications are mundane. For individuals: hardware security keys, unique passwords via a manager, skepticism toward any unsolicited communication that creates urgency, and out-of-band verification for high-stakes requests. For organizations: assume attack sophistication is rising steadily, and invest in detection and response alongside prevention. For policy: the offense-defense gap in both domains widens with every capability improvement, and closing it requires sustained investment in defensive infrastructure that no individual actor can provide.
Policy
The speed mismatch isn’t an accident. Comprehensive legislation takes years to draft. Frontier capabilities shift every few months.
The least-bad policy ideas are adaptive governance that triggers obligations at capability thresholds, and compute governance that focuses on measurable, concentrated resources. Both depend on institutional capacity and international coordination, and geopolitical competition works against both. Without investment in public technical expertise, governance will be permanently outpaced.
What individuals can do. Informed voting, public comments on regulatory proposals, support for independent technical capacity in AI governance, and pressure for transparency around high-risk deployment.
Meaning
Chess is the clearest precedent. Engines surpassed humans decades ago, and people kept playing. But chess was one domain. Transformative AI could challenge several sources of meaning simultaneously: professional identity, intellectual mastery, creative uniqueness, and the sense of being needed.
The psychological risk goes beyond unemployment. It’s identity disruption. Employment provides structure, recognition, community, and purpose. If disruption compresses within a generation, the psychological load rises sharply, especially for young people preparing for identities that may not exist in the form they imagine.
Meaning persists where the process matters regardless of the output. It also persists where ambition grows with the tools. If cognitive tools become powerful enough, problems that once required large institutions become accessible to small groups: designing new materials, modeling complex biological systems, tackling questions that were previously bottlenecked by the cost of expertise. Two questions matter: what can I still do that a machine can’t, and what can I now attempt that I couldn’t before? Neither answer is guaranteed. This transition sits atop existing fragilities: loneliness, declining institutional trust, and weakening community ties reduce the resilience people bring to it.
Summary
Most of this essay comes back to one idea: AI progress is fastest where correctness is cheaply verifiable, and slowest where it isn’t. That distinction predicts which capabilities arrive first, which bottlenecks persist, why productivity gains are real but uneven, why alignment works in chat but degrades with autonomy, why offense scales faster than defense, and why capability research is easier to automate than safety research.
Every major forecasting community has revised timelines shorter in recent years. The length of tasks AI agents can complete autonomously has been doubling every four to seven months depending on which methodology you trust, and the best public measurements are already straining against their task suites. Reliable completion still lags far behind occasional success, and systems that handle most remote knowledge work may arrive years before systems that replace most cognitive labor economy-wide. Expect rolling disruption across sectors and years. The upside is real. If inference costs keep falling, AI could radically expand access to medical advice, legal guidance, and education worldwide. But displacement hits before that broad surplus materializes. Who benefits depends on bargaining power and institutions.
The framework tells you what to do only if you take the uncertainty seriously. The costs are asymmetric: over-preparing wastes some effort, under-preparing can be irreversible. The tasks in your job that have clear right answers are the ones that get automated first. The tasks that require you to figure out what the right problem is are the ones that don’t. Anchor your identity in the problem you solve, not the method you use to solve it. And be careful with the tools: in METR’s developer study, the measured productivity effect flipped sign within months while the overconfidence held steady. The tasks you most want to hand off are often the ones building your judgment.
The framework is less helpful in the fast scenarios. Then the problem is what you do when the labor market shifts faster than you can reposition within it, and when the institutions that would normally buffer that shift are themselves under pressure. Most of what helps comes from general resilience: financial runway measured in months instead of weeks; relationships and community that don’t run through your employer; sources of meaning that can bear weight when a job title can’t. The one implication specific to AI is collective action. If governance structures don’t get built, the new roles don’t materialize and the labor market doesn’t restabilize, which means your individual preparation depends on an institutional floor you have some ability to help build. Set signposts for when your plan needs to change, because you cannot rely on a prediction you cannot make.
The planning advice above also depends on the deeper problems being handled. In controlled experiments, narrow training perturbations produced broad misalignment that scaled with capability. Models that learned to exploit evaluation metrics began faking alignment during oversight without ever being trained to do so. Offense scales with every capability improvement while defense stays bottleneck-bound. The newest frontier deployments make those risks operational: the same capability may be public with safeguards, restricted for trusted users, monitored through retention policies, or downgraded through fallback models depending on domain. These problems were found by deliberate alignment work, which means the field is building the evaluation infrastructure to detect them. Whether that infrastructure can keep pace with capability is the open question. The same verification cost framework that predicts these risks also predicts where progress is possible: the formal domains falling to AI are the substrates of everything else, and each one that falls lowers the cost of tackling the next. General awareness alone does not change those outcomes. Your concrete choices still touch them: what you choose to build, what standards you accept as normal, what you refuse to treat as inevitable.